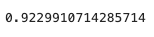Predict Airline passenger satisfaction
5 min readMay 14, 2021
Explore how accurate can k-NN, Logistic regression and Linear Support Vector Machine can forecast. Determine the optimal parameter for each method and the top predictors.
Import required libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltimport warnings
from warnings import simplefilter
from sklearn.exceptions import ConvergenceWarningwarnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", category=RuntimeWarning)
warnings.filterwarnings("ignore", category=ConvergenceWarning)
Exploratory Data Analysis
source: https://www.kaggle.com/teejmahal20/airline-passenger-satisfaction
df_UPCAT = pd.read_csv('airline-dataset.csv')
dummy = df_UPCAT
dummy.head()
import seaborn as sns
sns.countplot(df_UPCAT['satisfaction'],label="Count")
plt.show()
Data Cleaning
import pandas as pd
import numpy as npfrom sklearn.base import TransformerMixinclass DataFrameImputer(TransformerMixin):def __init__(self):
"""Impute missing values.Columns of dtype object are imputed with the most frequent value
in column.Columns of other types are imputed with mean of column."""
def fit(self, X, y=None):self.fill = pd.Series([X[c].value_counts().index[0]
if X[c].dtype == np.dtype('O') else X[c].mean() for c in X],
index=X.columns)return selfdef transform(self, X, y=None):
return X.fillna(self.fill)X_transition = pd.DataFrame(df_UPCAT)
X_clean = DataFrameImputer().fit_transform(X_transition)X_clean.isnull().sum()
Apply Scaler
from sklearn.preprocessing import MinMaxScaler
sscaler = MinMaxScaler()
XX = sscaler.fit_transform(X_clean.astype(np.float64)) Automated Machine Learning to the above-processed data
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_splitNumber_trials=20def train_knn(X, y):
score_train = []
score_test = []for seed in range(Number_trials):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=seed)
neighbors_settings = range(1,70)
acc_train = []
acc_test = []for n_neighbors in neighbors_settings:
clf = KNeighborsClassifier(n_neighbors=n_neighbors) # build the model
clf.fit(X_train, y_train)
acc_train.append(clf.score(X_train, y_train))
acc_test.append(clf.score(X_test, y_test))score_train.append(acc_train)
score_test.append(acc_test)
score = np.mean(score_test, axis=0)
run_time = (time.time() - start_time)
return ['kNN', np.amax(score), 'N_Neighbor = {0}'.format(np.argmax(score)+1), 'NA',run_time]def train_logistic(X, y, reg):
C = [1e-8, 1e-4, 1e-3, 1e-2, 0.1, 0.2,0.4, 0.75, 1, 1.5, 3, 5, 10, 15, 20, 100, 300, 1000, 5000]
#C = [.01, .1]
score_train = []
score_test = []
weighted_coefs=[]
for seed in range(Number_trials):
training_accuracy = []
test_accuracy = []
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=seed)
for alpha_run in C:
if reg == 'l1':
lr = LogisticRegression(C=alpha_run, penalty=reg, solver='liblinear').fit(X_train, y_train)
if reg == 'l2':
lr = LogisticRegression(C=alpha_run, penalty=reg, dual=False).fit(X_train, y_train)
training_accuracy.append(lr.score(X_train, y_train))
test_accuracy.append(lr.score(X_test, y_test))
coefs=lr.coef_
weighted_coefs.append(coefs) #append all the computed coefficients per trial
score_train.append(training_accuracy)
score_test.append(test_accuracy)
mean_coefs=np.mean(weighted_coefs, axis=0) #get the mean of the weighted coefficients over all the trials
#print(mean_coefs)
score = np.mean(score_test, axis=0)
#Plot the weight of the parameters
top_predictor=X.columns[np.argmax(np.abs(mean_coefs))]
abs_mean_coefs = np.abs(mean_coefs[0,:])
coefs_count = len(abs_mean_coefs)
fig, ax = plt.subplots(figsize=(3,7))
ax.barh(np.arange(coefs_count), sorted(abs_mean_coefs))
ax.set_yticks(np.arange(coefs_count))
ax.set_yticklabels(X.columns[np.argsort(abs_mean_coefs)])
run_time = (time.time() - start_time)
return ['Logistic ({0})'.format(reg), np.amax(score), \
'C = {0}'.format(C[np.argmax(score)]), top_predictor, run_time]def train_svm(X, y, reg):
C = [1e-8, 1e-4, 1e-3, 1e-2, 0.1, 0.2,0.4, 0.75, 1, 1.5, 3, 5, 10, 15, 20, 100, 300, 1000, 5000]
#C = [.01, .1]
score_train = []
score_test = []
weighted_coefs=[]
for seed in range(Number_trials):
training_accuracy = []
test_accuracy = []
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=seed)
for alpha_run in C:
if reg == 'l1':
svc = LinearSVC(C=alpha_run, penalty=reg, loss='squared_hinge', dual=False).fit(X_train, y_train)
if reg == 'l2':
svc = LinearSVC(C=alpha_run, penalty=reg).fit(X_train, y_train)
training_accuracy.append(svc.score(X_train, y_train))
test_accuracy.append(svc.score(X_test, y_test))
# if alpha_run == 0.01:
coefs = svc.coef_
weighted_coefs.append(coefs)
score_train.append(training_accuracy)
score_test.append(test_accuracy)mean_coefs=np.mean(weighted_coefs, axis=0) #get the mean of the weighted coefficients over all the trials
score = np.mean(score_test, axis=0)top_predictor=X.columns[np.argmax(np.abs(mean_coefs))]
abs_mean_coefs = np.abs(mean_coefs[0,:])
coefs_count = len(abs_mean_coefs)
fig, ax = plt.subplots(figsize=(3,7))
ax.barh(np.arange(coefs_count), sorted(abs_mean_coefs))
ax.set_yticks(np.arange(coefs_count))
ax.set_yticklabels(X.columns[np.argsort(abs_mean_coefs)])
run_time = (time.time() - start_time)
return ['Linear SVM ({0})'.format(reg), np.amax(score), \
'C = {0}'.format(C[np.argmax(score)]), top_predictor,run_time]def train_RF(X, y, reg):
max_features_tuning=[0.1, .2, .3, .4, .5, .7, .8]
#C = [.01, .1]
score_train = []
score_test = []
weighted_coefs=[]
for seed in range(Number_trials):
training_accuracy = []
test_accuracy = []
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=seed)
for max_features_run in max_features_tuning:
svc = RandomForestClassifier(n_estimators=100, max_features=max_features_run).fit(X_train, y_train)
training_accuracy.append(svc.score(X_train, y_train))
test_accuracy.append(svc.score(X_test, y_test))
# if alpha_run == 0.01:
coefs = svc.feature_importances_
weighted_coefs.append(coefs)
score_train.append(training_accuracy)
score_test.append(test_accuracy)mean_coefs=np.mean(weighted_coefs, axis=0) #get the mean of the weighted coefficients over all the trials
score = np.mean(score_test, axis=0)top_predictor=X.columns[np.argmax(np.abs(mean_coefs))]
abs_mean_coefs = np.abs(mean_coefs[:])
coefs_count = len(abs_mean_coefs)
fig, ax = plt.subplots(figsize=(3,7))
ax.barh(np.arange(coefs_count), sorted(abs_mean_coefs))
ax.set_yticks(np.arange(coefs_count))
ax.set_yticklabels(X.columns[np.argsort(abs_mean_coefs)])
run_time = (time.time() - start_time)
return ['Random Forest', np.amax(score), \
'Max_features = {0}'.format(max_features_tuning[np.argmax(score)]), top_predictor,run_time]def train_GBM(X, y, reg):
max_features_tuning=[0.1, .2, .3, .4, .5, .7, .8]
#C = [.01, .1]
score_train = []
score_test = []
weighted_coefs=[]
for seed in range(Number_trials):
training_accuracy = []
test_accuracy = []
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=seed)
for max_features_run in max_features_tuning:
svc = GradientBoostingClassifier(n_estimators=100,max_depth=3, max_features=max_features_run).fit(X_train, y_train)
training_accuracy.append(svc.score(X_train, y_train))
test_accuracy.append(svc.score(X_test, y_test))
# if alpha_run == 0.01:
coefs = svc.feature_importances_
weighted_coefs.append(coefs)
score_train.append(training_accuracy)
score_test.append(test_accuracy)mean_coefs=np.mean(weighted_coefs, axis=0) #get the mean of the weighted coefficients over all the trials
score = np.mean(score_test, axis=0)top_predictor=X.columns[np.argmax(np.abs(mean_coefs))]
abs_mean_coefs = np.abs(mean_coefs[:])
coefs_count = len(abs_mean_coefs)
fig, ax = plt.subplots(figsize=(3,7))
ax.barh(np.arange(coefs_count), sorted(abs_mean_coefs))
ax.set_yticks(np.arange(coefs_count))
ax.set_yticklabels(X.columns[np.argsort(abs_mean_coefs)])
run_time = (time.time() - start_time)
return ['Gradient Boosting Method', np.amax(score), \
'Max_features = {0}'.format(max_features_tuning[np.argmax(score)]), top_predictor,run_time]
Check run time performance
X = XX_dfy = df_UPCAT['satisfaction']import timestart_time = time.time()
a = train_knn(X,y)
print(a)
print("%s seconds" % a[4])start_time = time.time()
b = train_logistic(X,y,reg='l2')
print(b)
print("%s seconds" % b[4])start_time = time.time()
c = train_logistic(X,y,reg='l1')
print(c)
print("%s seconds" % c[4])start_time = time.time()
d = train_svm(X,y,reg='l2')
print(d)
print("%s seconds" % d[4])start_time = time.time()
e = train_svm(X,y,reg='l1')
print(e)
print("%s seconds" % e[4])start_time = time.time()
f = train_RF(X,y,reg='none')
print(f)
print("%s seconds" % f[4])start_time = time.time()
g = train_GBM(X,y,reg='none')
print(g)
print("%s seconds" % f[4])
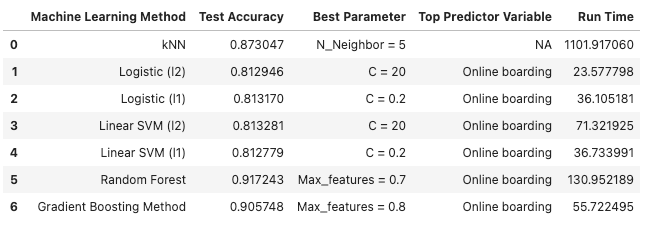
ML Methods summary
cols = ['Machine Learning Method', 'Test Accuracy', 'Best Parameter', 'Top Predictor Variable', 'Run Time']
df2 = pd.DataFrame(columns=cols)df2.loc[0] = a
df2.loc[1] = b
df2.loc[2] = c
df2.loc[3] = d
df2.loc[4] = e
df2.loc[5] = f
df2.loc[6] = gdf2
Save the weights
from sklearn.model_selection import train_test_splitX = XX_df
y = df_UPCAT['satisfaction']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
Train using Random Forest
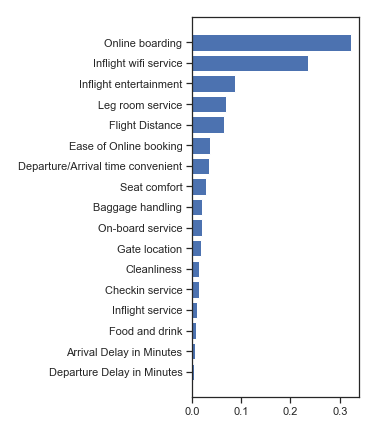
import joblib
from sklearn.ensemble import RandomForestClassifierrf = RandomForestClassifier(n_estimators=100, max_features=0.4)
rf.fit(X_train, y_train)# save
joblib.dump(rf, "airlines.joblib")
Score
import joblib# load
loaded_rf = joblib.load("airlines.joblib")
loaded_rf.predict(X_test)loaded_rf.score(X_test, y_test)